Introduction
The OU-ISIR Gait Database is meant to aid research efforts mainly in the general area of developing, testing and evaluating algorithms for gait-based human identification. The Institute of Scientific and Industrial Research (ISIR), Osaka University (OU) has copyright in the collection of gait database and serves as a distributor of the OU-ISIR Gait Database.
This inertial dataset was collected from visitors in a five day outreach event in 2011, in Tokyo, Japan. Each visitor was requested to sign an informed consent to permit the use of their data for research purpose. He/She also supplied the basic personal information such as gender and age. Thanks to them, we got the world largest database on inertial sensor-based gait. Detailed descriptions are found in the following:
- Thanh Trung Ngo, Yasushi Makihara, Hajime Nagahara, Yasuhiro Mukaigawa,Yasushi Yagi, "The largest inertial sensor-based gait database and performance evaluation of gait-based personal authentication," Pattern Recognition Vol.47 (1), pp. 228-237, 2014
News: We have uploaded the list of subjects with age and gender, please find the link at the bottom of the page.
Sensor Setup
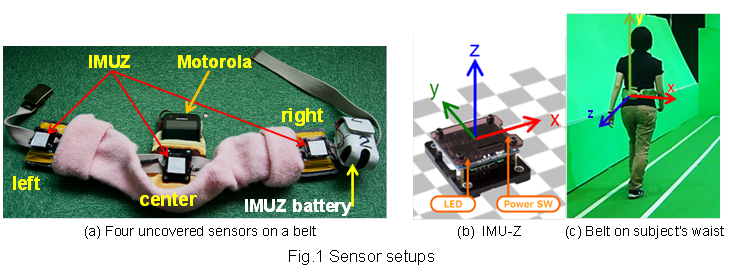
We used four sensors:
- 3 IMUZ sensors, each IMUZ includes a triaxial accelerometer and a triaxial gyroscope
- 1 smartphone, Motorola ME860, which includes only a triaxial accelerometer
Sensors are located around subject's waist as shown in Fig.1(a). The center IMUZ and Motorola are located at the center back waist of subjects, the left and right IMUZs are located at the left and right waist, respectively. Sensors worked at 100Hz.
Gait Styles

Fig.2 Walking path
Subject walked in and out the same designed path, Fig.2, where he/she made two level walk sequences for entering and existing, one sequence for up-slope, and one for down-slope walk, respectively.
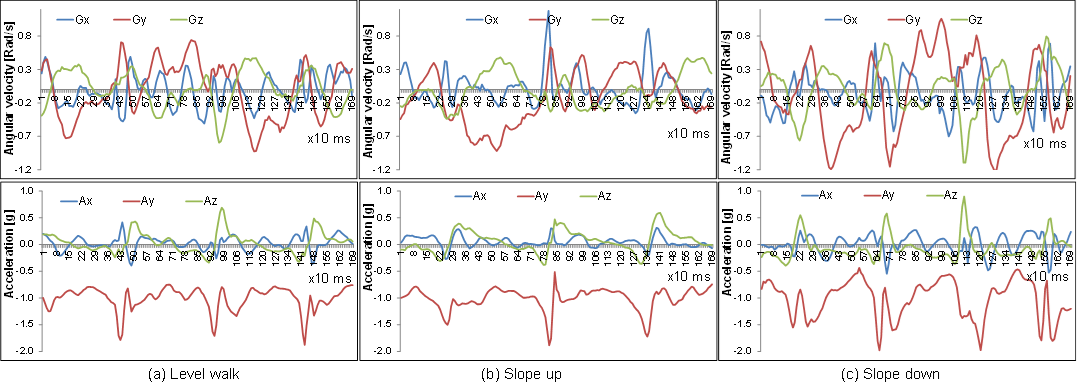
Fig.3 Examples of different gait styles of the same subject.
Dataset Information
After simple preprocessing to remove invalid data and extract interested data, we found that the validity of captured data was not equal for all subjects, hence our dataset could be optimized with respect to several variation factors. The most important factor is the number of subjects, therefore we made the first dataset that included the maximum number of subjects. Meanwhile, the second dataset was maximized with the variations of sensor location, ground condition, and sensor type, therefore the number of subjects was sacrificed for these variations.
- In the first subset, level walk data of 744 subjects (389 males and 355 females) with ages ranging from 2 to 78 years was captured by the center IMUZ. In this subset, two different level-walk sequences for each subject were extracted automatically by using motion trajectory constraint and signal autocorrelation.
- In the second subset, variations of ground slope and sensor location were focused. For each subject and each sensor, we extracted two sequences for level walk, a sequence for up-slope walk, and a sequence for down-slope walk. In total, we had a sub-subset from 3 IMUZ sensors for 495 subjects and a sub-subset from the smartphone for 408 subjects. In this subset, the data extraction for each sequence was performed manually by synchronizing with a simultaneously captured video.
File Name Convention
The filename contains ID and label of the sequence.
Example of naming convention for subject with ID= 000104:
- There are 4 sequences with different labels (level walk-1, level walk-2, up-slope, and down-slope walks) of the manually extracted subsets:
- T0_000104_Walk1.csv
- T0_000104_Walk2.csv
- T0_000104_SlopeDown.csv
- T0_000104_SlopeUp.csv
- T0_000104_Walk1.csv
- There are 2 sequences with labels (level walk-1, level walk-2) of the automatically extracted subset of the center IMUZ:
- T0_000104_Center_seq0.csv
- T0_000104_Center_seq1.csv
- T0_000104_Center_seq0.csv
File Format
Data file is formatted as follows:
- The first line contains the number of samples
- The second line contains the number of dimensions of the signal
- From the third line on, the first 3 components are for 3D gyroscope sample (Gx,Gy,Gz) and the last 3 components are for 3D accelerometer sample (Ax,Ay,Az).
- Unit of the gyroscope data is radian/s and that of the accelerometer is gravity [g].
For example, the content of file "T0_ID000104_Center_seq0.csv" is as follows:

Folder Structure
There are 2 folders for the first (automatically extracted) and the second (manually extracted) subsets, respectively, and 4 sub-folders of the manually extracted data:
 AutomaticExtractionData_IMUZCenter
AutomaticExtractionData_IMUZCenter- ManualExtractionData
- Android
- IMUZCenter
- IMUZLeft
- IMUZRight
Data Protocols in Our Paper
Most protocols used in our paper can be found in the folder Protocols of zipped file. However, for some experiments, the protocols are simple and we list them as follows:
- 5.4 Impact of sensor types and dissimilarity measures: the data subset is located in the folder IMUZCenter. You can refer to File Format to check how to get the gyroscope and accelerometer data. Level walk-1 sequences were used as galleries, while level walk-2 sequences were used as probes
- 5.5 Impact of ground slope conditions: the data subset is located in the folder IMUZCenter. You can refer to File Name Convention to check how to get the level, up-slope, and down-slope walk data. In this experiment, level walk-1 sequences were used as galleries, while sequences with other labels were used as probes.
- 5.8 Impact of sensor location around the waist: the second subset in folder ManualExtractionData was ussed. Similar to most experiments, level walk-1 sequences were used as galleries, while level walk-2 sequences were used as probes.
How to get the dataset?
To advance the state-of-the-art in gait-based human identification, this dataset could be downloaded as a zip file with password protection and the password will be issued on a case-by-case basis. To receive the password, the requestor must send the release agreement signed by a legal representative of your institution (e.g., your supervisor if you are a student) to the database administrator by mail, e-mail, or FAX.- Release agreement
- Download dataset
- Download ID list with age and gender
Note
It was often reported that Windows built-in zip did not work to extract all the files. Please try another unzip software if necessary.
The database administrator
Department of Intelligent Media, The Institute of Scientific and Industrial Research, Osaka UniversityAddress: 8-1 Mihogaoka, Ibaraki, Osaka, 567-0047, JAPAN
FAX: +81-6-6877-4375.